Infrastructure as a Service
Setup infrastructure to run Nextflow pipelines on-premises or in the cloud.
Run Nextflow pipelines at scale on your preferred infrastructure. We provide automated deployment for on-premises HPC clusters (Slurm) or cloud environments (AWS, GCP). Focus on your research while we handle the infrastructure.
Infrastructure Guides
Technical guides for setting up and managing HPC infrastructure. Each guide can be customized to your specific requirements.
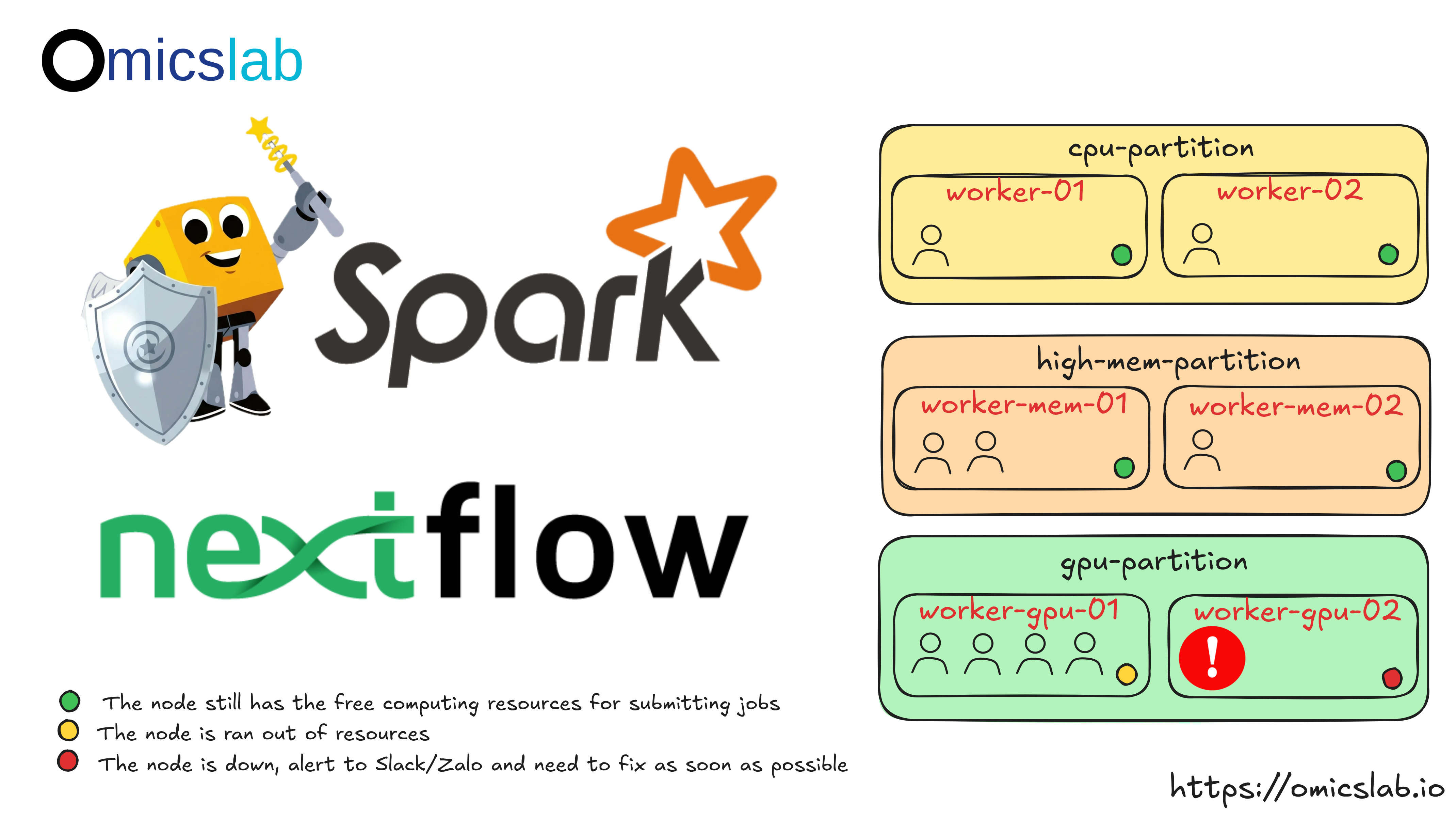
Slurm HPC Cluster Administration and Best Practices
In Part 1 and Part 2, we built a complete Slurm HPC cluster from a single node to a production-ready multi-node system. Now let's learn how to manage, maintain, and secure it effectively.
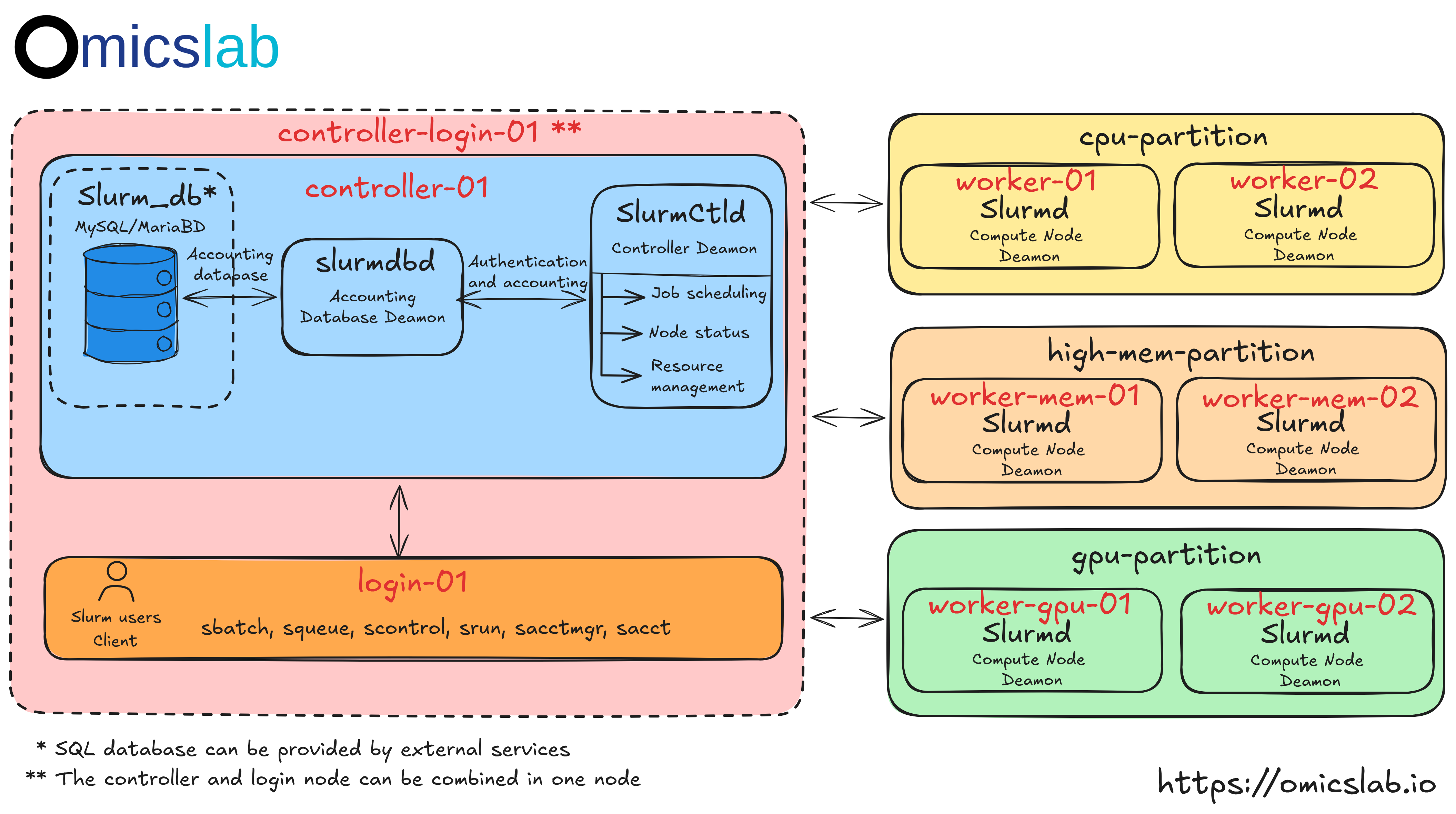
How To Scale a Slurm HPC Cluster to Production with Ansible
In Part 1, we learned the fundamentals by building a single-node Slurm cluster. Now it's time to scale up to a production-ready, multi-node cluster with automated deployment, monitoring, and alerting.
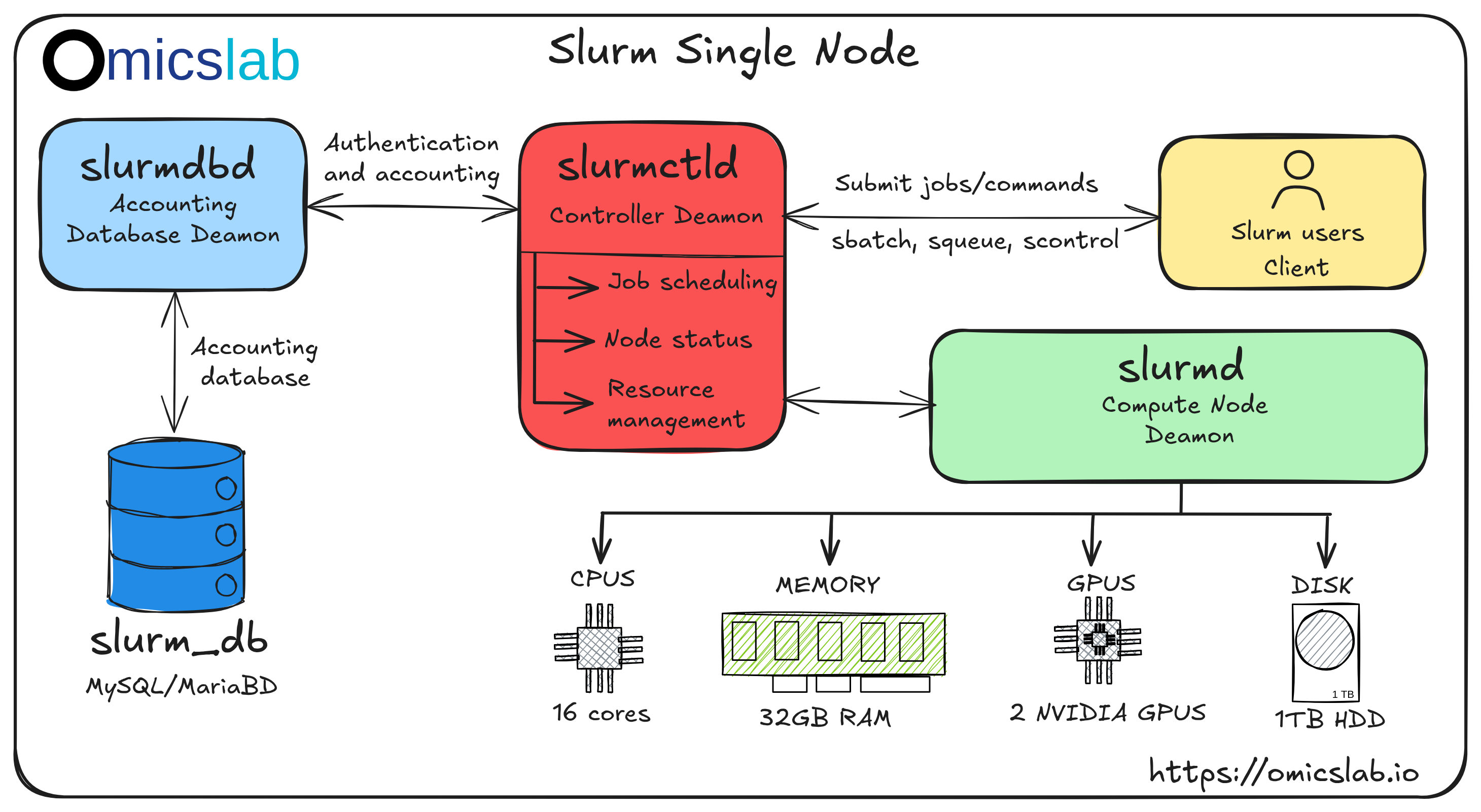
How To Build a Slurm HPC Cluster on a Single Machine
Building a High-Performance Computing (HPC) cluster can seem daunting, but with the right approach, you can create a robust system for managing computational workloads. This is Part 1 of a 3-part series where we'll build a complete Slurm cluster from scratch.
Available Infrastructure
On-Premises HPC
Deploy Nextflow on your local HPC cluster with Slurm, PBS, or LSF scheduler.
AWS Cloud
Run Nextflow on AWS Batch with EC2, Fargate, or Spot instances.
GCP Cloud
Deploy on Google Cloud Batch with Compute Engine or preemptible VMs.
On-Premises HPC
Deploy a complete Slurm HPC cluster on your local infrastructure. We provide the setup and configuration, you provide the hardware.
Mini-HPC
Small cluster for individual researchers or small labs
Configuration:
1 Controller/Login Node
1 Compute Node
Slurm Scheduler
NFS Shared Storage
Basic Monitoring
Includes:
Ansible automation setup
Slurm configuration
Nextflow integration
Basic training session
30-day support
* Hardware not included.
HPC Maintenance
Ongoing maintenance service for any HPC cluster
What's Included:
System updates and patches
Slurm version upgrades
Software package updates
24/7 monitoring
Priority support
* Works for any HPC cluster, including ones not set up by us.
Multi-Node HPC
Scalable cluster for research groups and production workloads
Configuration:
Multiple Controller Nodes (HA)
Multiple Compute Nodes
GPU Support (Optional)
High-Performance Storage
Advanced Monitoring
Includes:
Custom Ansible automation
High availability setup
LDAP/Active Directory | NIS
Full training sessions
1-year support
* Requirements vary.
Cloud Infrastructure Features
Auto-Scaling
Automatically scale compute resources based on workload.
Cost Optimization
Use spot/preemptible instances for batch jobs. Save up to 90%.
Job Monitoring
Real-time monitoring of pipeline execution.
Storage Integration
Connect to S3, GCS, or local NFS storage.
Let's work together on your bioinformatics needs.
Our Location
Ho Chi Minh City, Vietnam
Email Us
contact@omicslab.io